
はじめに
Pythonを利用してスクレイピングをする機会があるのですが、初学者の時はとにかく何から勉強したらいいかわからないことだらけで困りました。
ざっくりと、感覚からでも理解したい方もいるかと思って、記事にしてみましたので参考にしてみてください。
今回の記事では、色々な知識をかじりつつ簡単なコードを動かすところまで解説しています。
この記事は、windowsユーザーで
・そもそもシステム初学者
・システムに詳しくはないけどスクレイピングを使って業務効率化してみたい
・副業でスクレイピングを使いたい
な方に向けた内容になるかと思います。
環境/前提知識
・Windows11環境(10環境でも可能です)
・Visual Studio Code
・ローカルPCでPythonを使える環境構築が完了している
→環境構築と前提知識については前回の記事を参照してください
今回利用するコード
import requests
from bs4 import BeautifulSoup
url = 'https://fukugyo-shacho.jp/blog'
responce = requests.get(url)
soup = BeautifulSoup(responce.text, 'html.parser')
title = soup.find('h1')
print(title.text)しばらくはこのコードにお世話になります。
このコードは、副業社長のサイトの記事一覧ページ(https://fukugyo-shacho.jp/blog)から、タイトル情報をとってくることを目的にしています。
まずは、このコードをVisual studio Codeに貼り付けて動かしてみてください。
成功すると、「ブログ」という文字列が表示されます。
(サイトのサーバーへの負担があるため、何度もコードを実行するのはご遠慮ください)
今回の目標
今回の目標は、ざっくりとこのコードがどんな動きをしているかになります。
実際に仕組みや詳しい解説は次回以降に解説しますが、一度どの部分がどんな動きになっているかを確認してみます。
私自身、一度ざっくりとあらましを掴んでから、後々知識を深めていくやり方の方が理解しやすかったので、まずは動くことを確認してみましょう。
コードを4つの部位に分けてみる
いきなりコードを見ると複雑に見えるかもしれませんが、画像のように分けてみると・・・
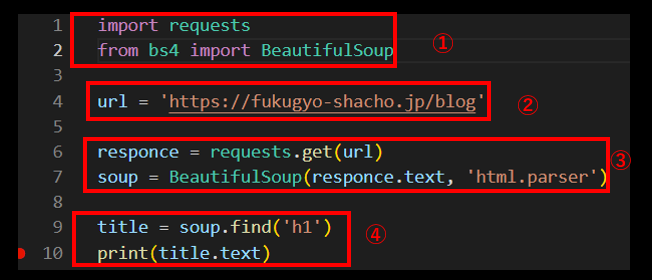
意外とすっきりして見えると思います。
それぞれ何をやっているかを見てみましょう。
① モジュールのインポート
import requests
from bs4 import BeautifulSoup最初の部分では、「モジュール」をインポートしています。
モジュールは、今回のコードを書くための工具箱のようなものだと思ってください。
スクレイピングをするには、スクレイピング用の工具が必要になります。
そのセットが入った工具箱を用意しているわけです。
今回インポートしたモジュールは「requests」と「BeautifulSoup」ですね。
Pythonで使う各用語の解説と、2つのモジュールの詳細については次回以降に改めて行いますので、ここではなんとなくの理解で構いません。
② データを取得したいページのURLを指定する
url = 'https://fukugyo-shacho.jp/blog'2つ目の部分では、どのページの情報を取得したいのかを指定しています。
今回アクセスするページのURLをプログラムに教えてあげるイメージです。
厳密には少し違うのですが、一旦はそんなイメージで問題ありません。
このあたりは「変数」がわかれば理解できると思います。
③ 指定したURLのHTML情報を取得して解析する
responce = requests.get(url)
soup = BeautifulSoup(responce.text, 'html.parser')この部分はスクレイピングの肝になります。
最初の文で、①で用意したモジュールの中にある「関数」を使って、②のURLのページへ「リクエスト」してHTML(ページのソースコード)を取得しています。
次の文では、取得したHTMLを「解析」して、データを探せる形に整えています。
このあたりの話になると少し専門的な用語も出てきます。
仕組みとしては多少複雑な内容を理解する必要があるので、最初のうちはテンプレートだと思って文章そのままに覚えてしまうのがいいと思います。
④ 解析した内容からタイトル情報を探す
title = soup.find('h1')
print(title.text)4つ目の項目の最初の文では、③で解析したHTMLから、「find関数」を使ってタイトル(h1)を探しています。
最後に、見つけたデータを「print」で画面に表示してコードは終了となります。
実は①~③までの内容は、慣れてしまうとルーティンのように書くことができるのですが、ここだけはしっかりした知識がないと、欲しいデータを取得するのが難しくなってしまいます。
というのも、取得したいデータは目的によって違います。
画像のURLが取りたいときもあれば、数値のデータを取得して表にしたいときもあるでしょう。
インターネットには、Pythonスクレイピングについてわかりやすく解説したページや動画が多くありますが、ここだけはどうしても簡潔に説明するのが難しいです。
実際に、私も実務で使って躓いたのは、ほとんどがこの部分でした。
おわりに
今回の記事では、簡単にコードがどのようにして動いているかを解説してみました。
ある程度自分の中の知識がまとまってきたと思ってこのシリーズを書き始めてみましたが、実際に説明するのは難しいですね。
それでも、今後少しずつ解説するつもりですので、続きをお待ちいただけると幸いです。
